
My PhD
When I started my PhD in 2021, language models like BERT were established tools, but they had several practical limitations for real-world text classification work:
- Data requirements: They still required relatively large amounts of balanced training data to work well on new tasks, as they only come with prior language-knowledge, but have no useful prior task-knowledge from pre-training.
- Multilingual performance: While models like XLM-R had shown good performance on narrow multilingual benchmarks, it was unclear if these models produce valid measurements across different languages and cultures.
- Bias and validity: They were susceptible to learning shortcuts and biased patterns from their training data, reducing the validity of measurements across social groups.
- Accessibility: They were difficult to use, making them only accessible to specialised researchers.
My dissertation consists of four main papers that demonstrate empirically how each of these four limitations can be addressed with instruction-based language models. I specifically investigate one variant of instruction-based language models: BERT-NLI. The dissertation used recent insights from the NLP literature and applied it to practical problems in the computational social sciences.
Published as: Laurer, Moritz (2024). Language Models as Measurement Tools: Using Instruction-Based Models to Increase Validity, Robustness and Data Efficiency. [PhD-Thesis - Vrije Universiteit Amsterdam]. https://doi.org/10.5463/thesis.742
1. Paper: Addressing the Data Scarcity Issue
This paper (Chapter 2) shows how the instruction-based BERT-NLI model can reduce the required training data by a factor of ten compared to older algorithms, while achieving the same level of performance across eight tasks, especially on imbalanced data. The paper also explains the importance of both language- and task-knowledge for real-world imbalanced tasks. Download paper.
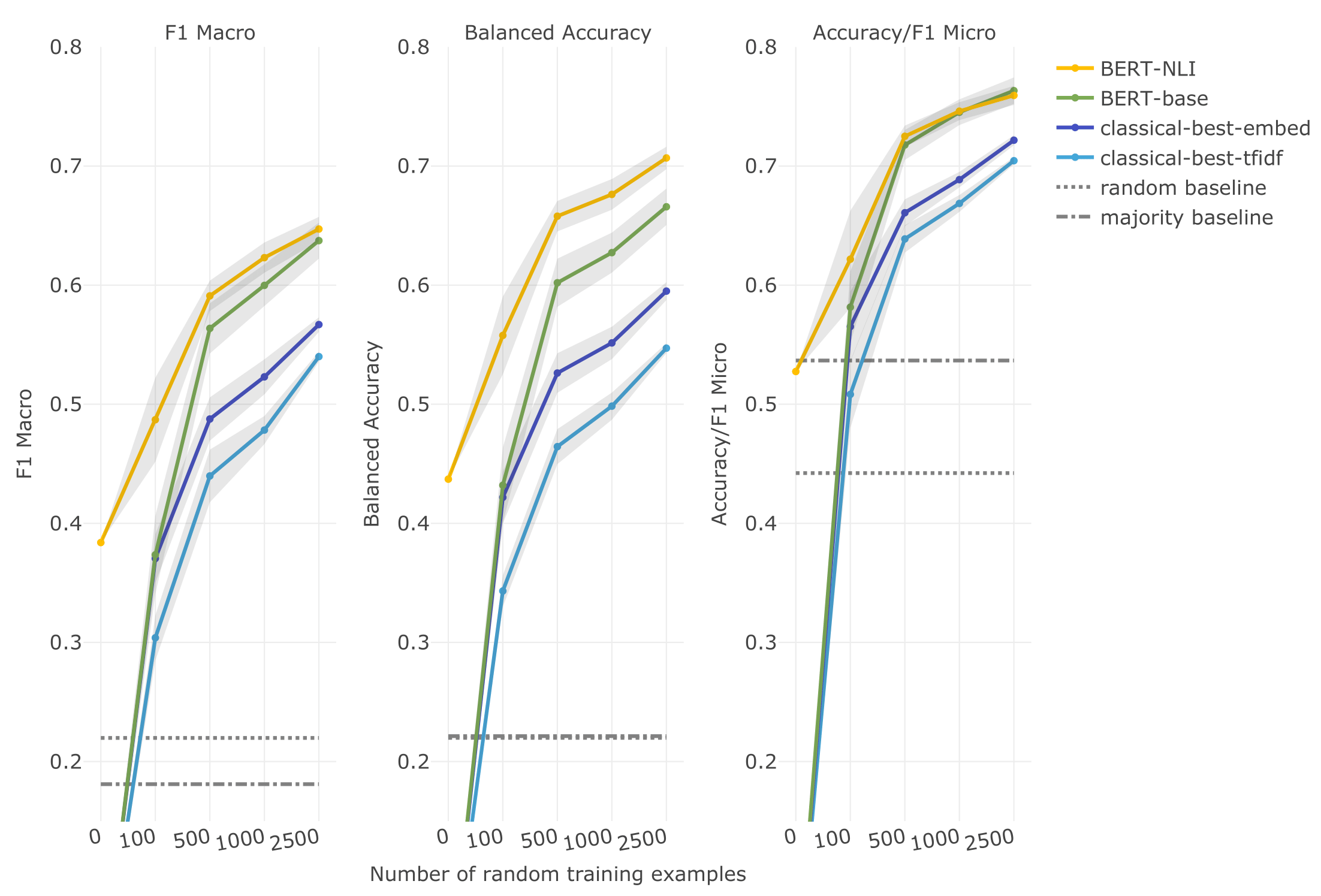
Published as: Laurer, M., Van Atteveldt, W., Casas, A., & Welbers, K. (2023). Less Annotating, More Classifying: Addressing the Data Scarcity Issue of Supervised Machine Learning with Deep Transfer Learning and BERT-NLI. Political Analysis, 1–33. https://doi.org/10.1017/pan.2023.20
2. Paper: Lowering the Language Barrier
This paper (Chapter 3) compares different approaches to creating valid measurements from multilingual data using two datasets with texts in 12 languages from 27 countries. The paper shows that BERT-NLI models trained on only 674 or 1,674 texts in only one or two languages can validly predict political party families’ stances towards immigration in eight other languages and ten other countries. Download paper.

Published as: Laurer, M., Van Atteveldt, W., Casas, A., & Welbers, K. (2023). Lowering the Language Barrier: Investigating Deep Transfer Learning and Machine Translation for Multilingual Analyses of Political Texts. Computational Communication Research, 5(2), 1. https://doi.org/10.5117/CCR2023.2.7.LAUR
3. Paper: Increasing Validity and Decreasing Bias with Instructions
This paper (Chapter 4) shows how BERT-NLI models are more robust against group-specific biases in training data. BERT-NLI sees its average test set performance decrease by only 0.4% F1 macro when trained on biased data and its error probability on groups it has not seen during training increases only by 0.8%, as shown in a comparative analysis across nine group types in four datasets with three types of classification models. Download paper.
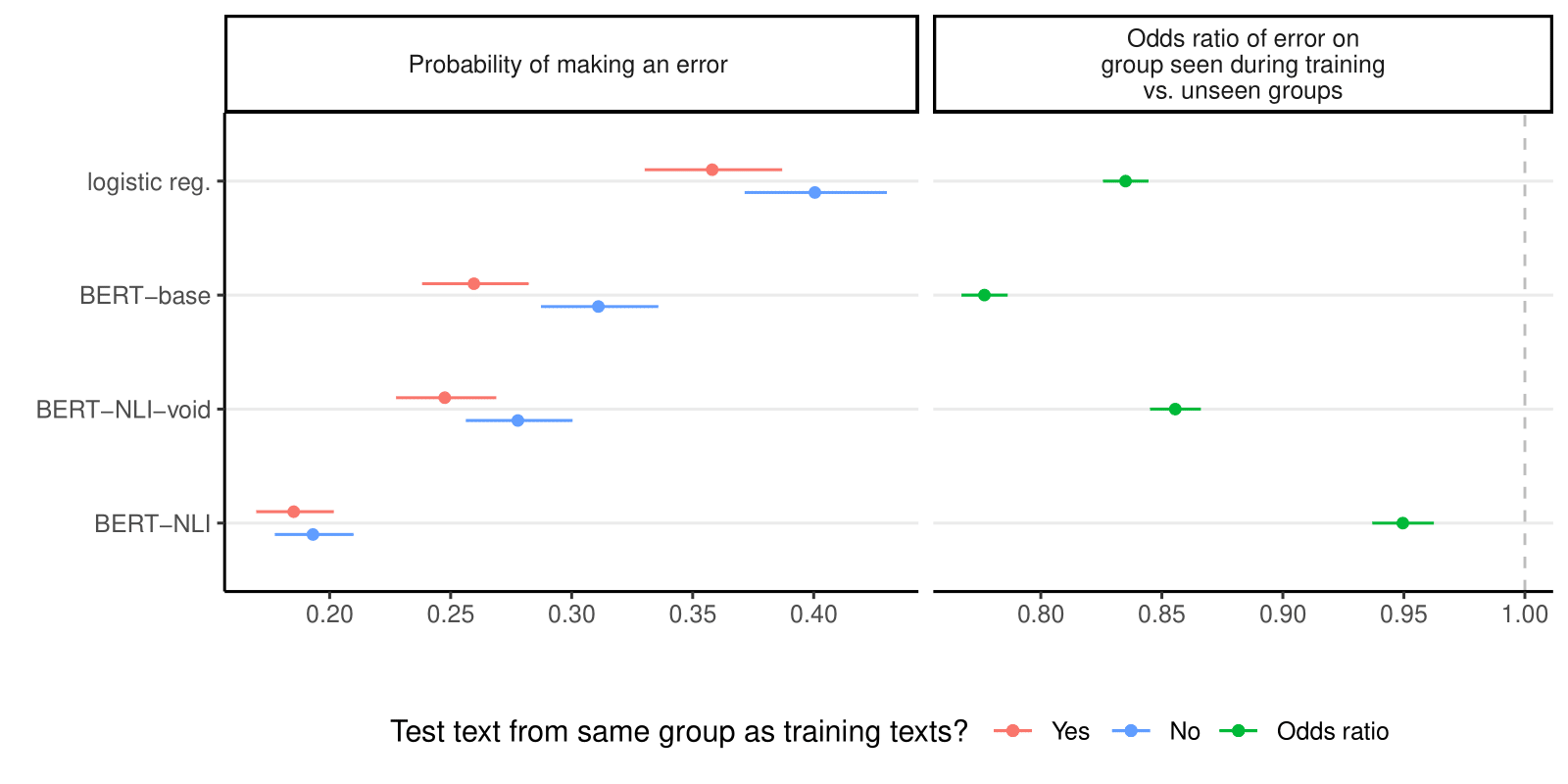
Published as: Laurer, M., van Atteveldt, W., Casas, A., & Welbers, K. (2024). On Measurement Validity and Language Models: Increasing Validity and Decreasing Bias with Instructions. Communication Methods and Measures, 1–17. https://doi.org/10.1080/19312458.2024.2378690
4. Paper: Building Efficient Universal Classifiers with NLI
This paper (Chapter 5) first (a) explains how Natural Language Inference (NLI) can be used as a universal classification task that follows similar principles as instruction fine-tuning of generative LLMs, then (b) provides a step-by-step guide with reusable Jupyter notebooks for building a universal classifier, and then (c) shares the resulting universal classifier that is trained on 33 datasets with 389 diverse classes. Download paper.
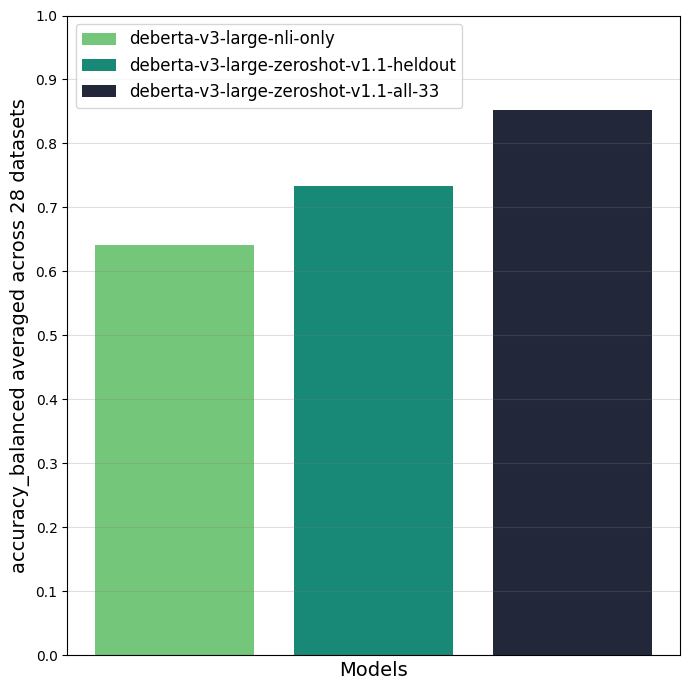
Published as preprint: Laurer, M., van Atteveldt, W., Casas, A., & Welbers, K. (2023). Building Efficient Universal Classifiers with Natural Language Inference (arXiv:2312.17543). arXiv. https://doi.org/10.48550/arXiv.2312.17543